Answer
To keep the CPU from blocking when it dispatches compute kernels, the GPU maintains a queue of kernel calls - the CUDA launch queue. This can be thought of as an example of the producer-consumer pattern, where the CPU is the producer and the GPU is the consumer.
It takes time to send the kernel from CPU to GPU (the “kernel launch delay”), and for small kernels, this time can exceed the time taken to execute the kernel on GPU.
Equipped with this knowledge, we can interpret the PyTorch Profiler trace as follows:
- In Block 1, the GPU takes long enough to perform the large multiply for the queue to fill up with the small kernels. When the large matrix multiply finishes, the GPU immediately starts executing the enqueued small matrix multiplies.
- In Block 2, the GPU completes each small matrix multiply before the next one is available, so it idles between the small kernels.
If we increase the number of small matrix multiplications in large_small, after roughly 35 small matrix multiplies the gaps reappear. This is because the queue eventually drains, exposing the kernel launch delay again.
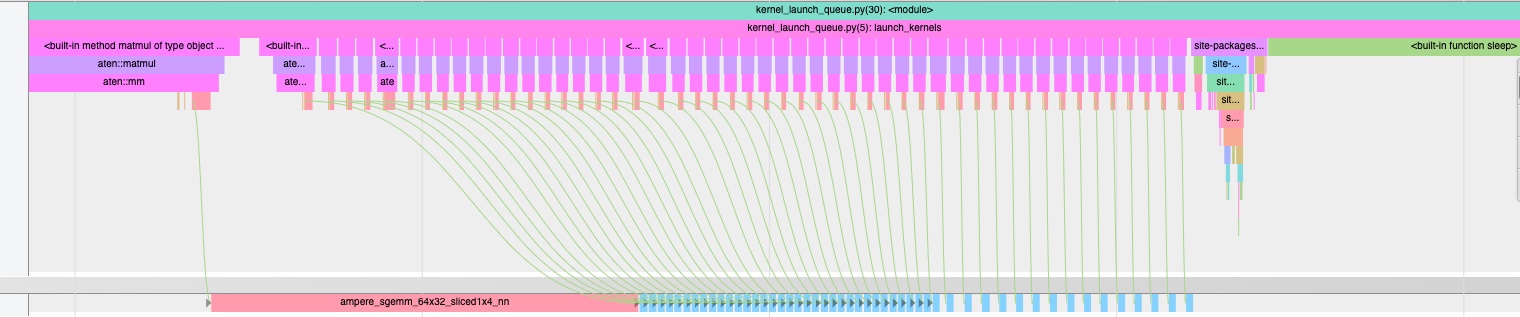 With more small multiplications, the launch queue drains
With more small multiplications, the launch queue drains
Discussion
What is the CUDA kernel launch queue?
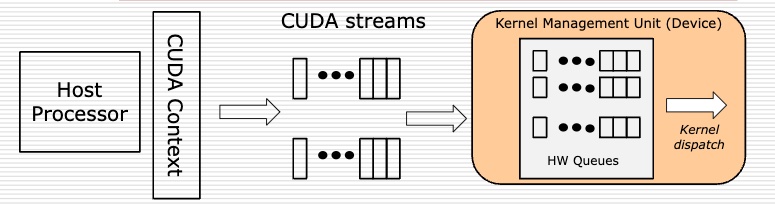 CUDA kernel launch queue
CUDA kernel launch queue
The GPU maintains a queue of kernel calls in the order they are made by the CPU. Some salient facts about this queue include:
- The queue is hardware-managed: kernels launch when required resources become available.
- If the launch queue reaches a threshold (1024 entries), the CPU will block on calling a compute kernel. This can be problematic if there is other work the CPU could be doing, and should be avoided.
- Each queue entry is quite small: under 4 KB of kernel params. (Even though a kernel may operate on huge tensors, the queue entry will use their GPU memory addresses.)
What is the root-cause of the kernel dispatch overhead?
Specifically, what happens in the time from when a Python method is invoked to when the kernel actually starts executing on the GPU? A common guess is that the overhead comes from PCIE, but this is incorrect. Proof comes from comparing the Kineto trace for our PyTorch program to the NSight Systems (NSYS) trace for the functionally equivalent CUDA C program.
 Big and small matrix multiplications in CUDA C
Big and small matrix multiplications in CUDA C
For the CUDA program we see almost no difference between launching the large gemm first and the small gemms first. In particular the gaps between kernels is very small in both cases.
- Note that the actual kernel calls are identical and have the same duration
- Big: ampere_sgemm_64x32_sliced1x4_nn, Small: ampere_sgemm_32x32_sliced1x4_nn
- NSYS trace file, CUDA source code
PyTorch is supposed to be a thin veneer around NVIDIA library code. However, the reality is that the combination of PyTorch, PyBind, Python, and, ultimately, the C++ dispatcher is very expensive. There are many operations involved in dispatch:
- Parsing arguments
- Finding the right function to dispatch (v-table, signature scanning)
- Object construction in Python, C++, as well as the GPU. This involves memory allocations - note that there’s lots of memory overhead for small objects.
- Stride calculation (done on host side, made complex by possibility of aliasing)
TensorFlow on GPU is even slower than PyTorch: it adds one more layer of indirection via protobuf. (NSYS trace file, TensorFlow source code)
 Big and small matrix multiplications in TensorFlow
Big and small matrix multiplications in TensorFlow
How can we reduce the kernel launch overhead?
-
Don’t let the queue empty
A non-empty queue hides the launch overhead. We can keep the queue nonempty by avoiding synchronization/ganging up synchronization events wherever possible As an example, the CUDA Caching Allocator avoids calling cudaFree() which is a synchronizing event by recycling memory within streams (Details: source code, also Zachary DeVito’s blog post).
Reordering independent kernels to send big kernels before small ones also serves to keep the queue from emptying, just like in our working example.
-
Replace lots of small kernels with a few big ones
The key idea of fusion is to combine kernels. There are two basic approaches to fusion:
- Horizontal Fusion, in which independent kernels (i.e., kernels with no data-dependencies) are
merged.
- E.g.,
torch._foreach_mul(P, Q)where P, Q are lists of matrices - See this link for the comprehensive list of
torch._foreachmethods (link). - There’s more manual approaches to horizontal fusion, e.g., keep matrices A, B, C as a single 3D tensor.
- E.g.,
- Vertical Fusion in which interdependent kernels are “in-lined”, e.g.,
A.pow_(3.14).mul_(2.71).add_(0.577)can be replaced by a single kernel.
Fusion doesn’t just reduce launch overhead: it can also avoid repeated memory reads/writes, and is a great way to increase arithmetic intensity for vector operations. See the To Fuse or Not to Fuse? puzzler for an example.
- Horizontal Fusion, in which independent kernels (i.e., kernels with no data-dependencies) are
merged.
-
Use CUDA Graphs
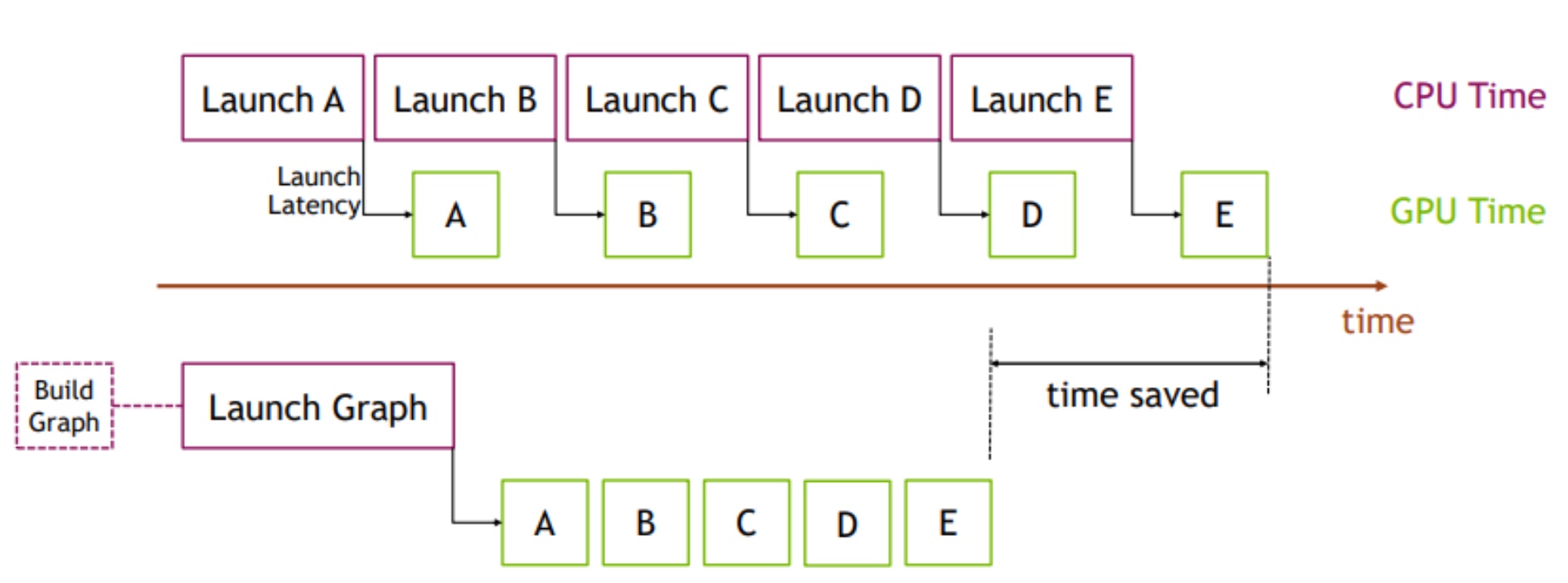 CUDA Graph Overview
CUDA Graph Overview
Real ML programs are repetitive, e.g., training has millions of iterations. The data changes but the computation remains the same.
The basic idea of CUDA Graphs is to record computation and memory addresses and replay them. Here’s CUDA Graphs applied to this puzzler: source code, and the PyTorch Profiler trace.
Reference: Accelerating PyTorch with CUDA Graphs
 CUDA Graph applied to big and small matrix multiplication
CUDA Graph applied to big and small matrix multiplication
-
Eschew PyTorch
The AI Template approach is to do it all in CUDA C - currently, it’s inference only.
The tch-rs project adds Rust bindings for the C++ API of PyTorch. Rust is a “modern systems programming language focusing on safety, speed, and concurrency; it accomplishes these goals by being memory safe without using garbage collection.” However, tch-rs is not much better than PyTorch with respect to dispatch overhead because it inherits the C++ dispatcher from PyTorch, which is where the majority of dispatch overhead comes from.
 Big and small matrix multiplications in Rust
Big and small matrix multiplications in Rust
What should you remember in years to come?
PyTorch kernel launch overhead can kill performance - keeping queues from emptying, kernel fusion, CUDA Graphs, and eschewing PyTorch are solutions.
Explore more
-
With PyTorch 2.0,
torch.compile()does many fusions automatically. It’s also exceptional at GPU code generation. -
You can also try writing your own fused kernel in CUDA C and binding it to PyTorch.