Memorable Mysteries
Puzzler 1
The code snippet below copies a large tensor from the CPU to the GPU. The copy takes place through the PCIe connection to the GPU. If you compute the effective bandwidth on an A100 (40 GB) it comes to about 4.2 GB/sec, far below the advertised performance of 16 GB/s for PCIe v3 - why?
N = 2**32
Acpu = torch.rand(N)
Agpu = torch.empty(N, device='cuda')
Agpu.copy_(Acpu)
Puzzler 2
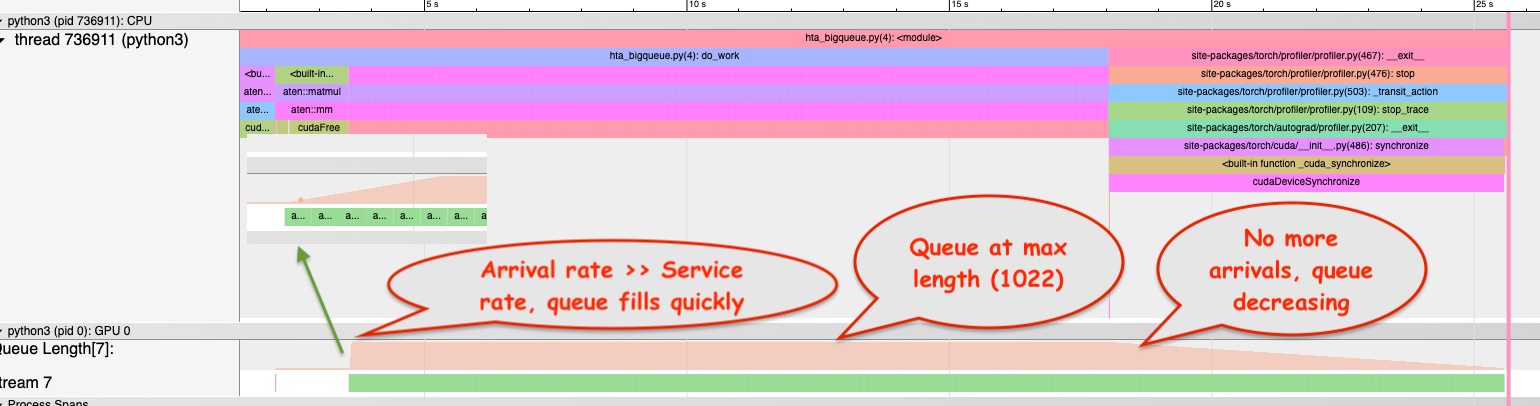
The code below iteratively squares a large matrix. Each resulting matrix takes $4
\cdot 4096 \cdot 4096 \; \textrm{bytes} \approx 67$ MB. The matmul() calls are relatively slow,
and the trace shows that there are as many as 1022 kernels in the launch queue. When the matmul
kernel is enqueued, it gets a pointer to memory holding $A$ and a pointer to memory into which it
will write the result. There are 1022 kernels enqueued and we need to reserve $1022 \cdot 67 \approx
68.6$ GB of memory. This is more than the 40 GB of memory on the A100 (40 GB) GPU. However, the
program does not OOM - why?
torch.backends.cuda.matmul.allow_tf32 = False
A = torch.rand((4096, 4096), device='cuda', dtype=torch.float32)
for i in range(3000):
Asquare = torch.matmul(A, A)
Puzzler 3
This code snippet computes the transpose of a matrix. For a $4096 \times 4096$ matrix, it’s 200x
slower than calling A.transpose(0,1).contiguous(). Why?
# Assumption: A is a square matrix.
def transpose(A):
result = torch.empty_like(A)
N = A.size()[0]
for i in range(N):
result[i,:] = A[:,i]